Relocation works for both graceful and abrupt departures. On a graceful shutdown the departing node replicates a
PeerState snapshot to its oldest peers. On a crash (kill -9, OOM, network partition) that snapshot never gets written, so the leader instead reconstructs the departed node’s relocation set from the replicated cluster registry. Actors spawned with WithRelocationDisabled are still lost with the node either way.When relocation happens
Relocation is triggered when:- A node leaves the cluster: The cluster membership layer (Hashicorp Memberlist) detects the departure and emits a
NodeLeftevent. - The departed node had relocatable actors or grains: Only actors spawned with relocation enabled (the default) and grains without
WithGrainDisableRelocationare eligible.
Relocation flow
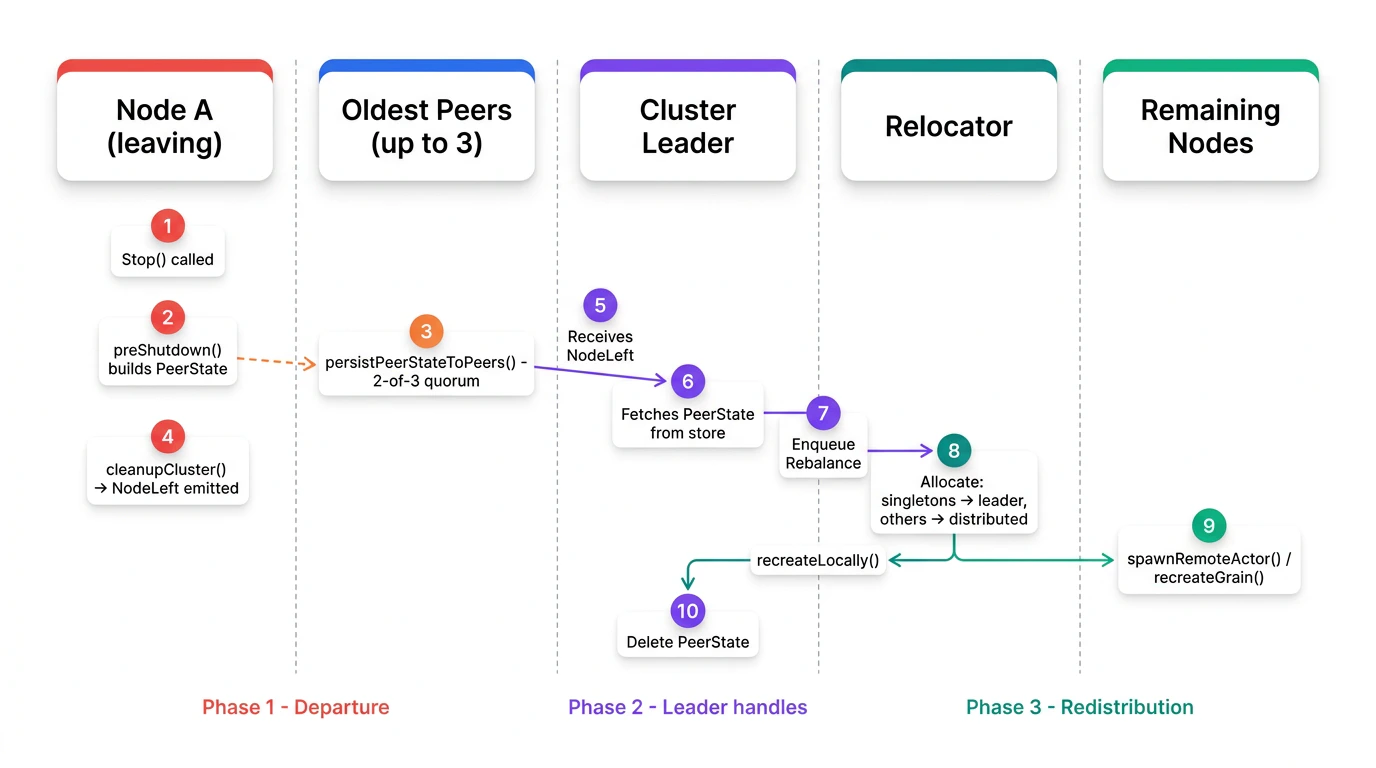
Key steps
- preShutdown: When a node stops, it builds a
PeerStatesnapshot of all relocatable actors and grains. Actors withWithRelocationDisabledand grains withWithGrainDisableRelocationare excluded. - persistPeerStateToPeers: Before leaving membership, the node replicates its
PeerStateto up to 3 oldest cluster peers via RPC (not all remaining peers). The implementation usesselectOldestPeers(3)to pick the three oldest nodes byCreatedAt; if fewer than 3 peers exist, it replicates to all. Replication returns successfully as soon as 2-of-3 peers acknowledge (quorum); remaining RPCs are cancelled. Each peer stores the state in its local cluster store (e.g. BoltDB). The oldest peers are chosen because leadership is determined by node age (the oldest nodes are most likely to remain or become leader when the departing node leaves), so the new leader will have the state when it handlesNodeLeft. - cleanupCluster: The departing node removes its actors and grains from the cluster map (Olric) and, if leader, removes singleton kinds. This runs after persist and before leaving membership.
- NodeLeft: The cluster emits a
NodeLeftevent. The leader node handles it: it fetches the departed node’sPeerStatefrom its local cluster store (the leader must have been one of the up-to-3 peers that received the state). If no snapshot is found (the usual case for a crash), the leader instead derives the relocation set from the replicated registry (see Crash recovery below). Either way it then registers an in-flight relocation job for the departed address and sends aRebalancemessage to the relocator. A duplicateNodeLeftfor an address whose relocation is still in flight is ignored; once the relocation completes, a later departure of the same address is rebalanced again. - Relocation worker: The relocator spawns a short-lived worker per departed node, so relocations of distinct nodes proceed concurrently. The worker:
- Allocates actors: singletons go to the leader; non-singletons are distributed across the leader + eligible peers, honoring each actor’s required role.
- Allocates grains across leader + peers the same way; each target then dispatches on the grain’s own relocation intent. Lazy grains (the default) are not reactivated upfront: the target only cleans their directory entry so the next
TellGrain/AskGrainre-activates them on a live node. Eager grains (opted in withWithGrainEagerRelocation) are recreated up front like actors. - Handles the leader’s share locally (via
SpawnSingletonfor singletons). - Hands each peer its whole share in batched
RelocateBatchrequests (at most 500 items per request) instead of one RPC per actor. The target node recreates or releases the items and reports failures per item. - Cleans up stale registry entries with gating: an entry is removed only when it still points at the departed node. An entry pointing at a live node means the item was already recreated elsewhere and is skipped.
- Completion: The worker publishes the outcome, deletes the departed node’s state from the cluster store, releases the relocation job, and stops.
Failure handling
Item failures are isolated: a failing actor, grain, or peer never aborts the rest of the rebalance.- Each batch request is attempted twice with a short backoff before its target peer is considered unreachable.
- When a peer is unreachable, the unsent remainder of its share is moved once to the next surviving peer.
- Each individual item (actor respawn, eager grain reactivation, lazy grain release) is retried a bounded number of times with backoff before it counts as failed: relocation runs while the cluster is still digesting a node loss, so registry operations can transiently time out.
- A failed actor respawn restores the actor’s registry record before the failure is reported, so the actor stays visible and recoverable (by a later departure-triggered relocation or the node’s own restart reconciliation) instead of being silently erased.
- Items that still cannot be relocated are reported in a single
RelocationFailedevent on the event stream, listing exactly the failed actor addresses and grain identities. Items that were relocated are not listed. - A failed lazy-grain release is never reported: it is a cleanup optimization, not an item loss. The directory entry self-heals when the grain is next addressed.
Relocation events
Every relocation run publishes two events on the event stream:RelocationStarted when the leader establishes the relocation set, and RelocationFailed when items could not be relocated. Subscribe with ActorSystem.Subscribe() to observe or react to relocations; both events are cluster mode only.
RelocationStarted
Published by the leader whenever it starts relocating a departed node’s actors and grains, for graceful shutdowns and crashes alike.BestEffort() distinguishes the two departure paths:
false(graceful shutdown): the set comes from thePeerStatesnapshot the departed node replicated before leaving, and is complete.true(crash): the node left no snapshot, so the set was reconstructed from the replicated cluster registry (see Crash recovery). Records lost with the crashed node’s partitions cannot be listed, so the set may be incomplete even though relocation of the listed items proceeds normally. The event fires even when the reconstructed set is empty, which signals suspected record loss rather than a benign no-op. Subscribers holding an external record of placements can diff it against the listed items to detect and reconcile silent losses.
RelocationFailed
Published when items of a departed node could not be relocated after all retries. It lists exactly the failed items; items that were relocated successfully are never listed.
The report is terminal: the relocation run does not revisit failed items. Subscribe to this event to drive your own recovery, for example re-spawning the affected actors, alerting, or adding capacity for a missing role.
Subscribing
Actor allocation
Only relocatable actors are recreated. Actors with
WithRelocationDisabled are skipped. System actors (e.g. dead letter, scheduler) are never relocated.
Placement is load-aware: before distributing the departed node’s actors, the leader scans the replicated cluster registry once and seeds each target’s “load” with the number of actors it already hosts. The departed node’s actors then flow to the nodes that are least loaded overall, rather than merely being split evenly among the surviving targets. This prevents a survivor that was already busy (often the leader, which also takes singletons) from being over-assigned. The scan is best-effort: if it fails (e.g. degraded cluster quorum) placement transparently falls back to an even split of the departed node’s actors.
Role-aware allocation
When an actor is spawned withWithRole, relocation only considers nodes that advertise that role (the same constraint that governs initial placement). The worker assigns each role-constrained actor to the least-loaded eligible target among the leader and surviving peers; role-less actors are eligible everywhere.
If no surviving node advertises the required role, the actor cannot be relocated. It is reported in the RelocationFailed event rather than being silently dropped, so you can subscribe and react (add capacity for that role, or relax the constraint). Singletons are always routed to the leader share, where the cluster singleton spawn path re-arbitrates their placement (including any role constraint).
Crash recovery
Relocation does not depend on a clean shutdown. There are two sources for a departed node’s relocation set:- Graceful-shutdown snapshot: the departing node replicated a
PeerStateto its oldest peers before leaving (the steps above). - Registry-derived set (crash fallback): when the leader finds no snapshot for the departed address, it reconstructs the set by scanning the replicated cluster registry for every actor and grain still hosted on that node.
host:peersPort, carried by the NodeLeft event) to its remoting address (host:remotingPort, how records are keyed). The cache is seeded from membership when clustering starts and refreshed on every NodeJoined, so a node observed alive at any point remains resolvable when it later crashes. The derived set contains only relocatable actors and the departed node’s grains; from there it flows through the exact same worker, gating, and failure-reporting path as the graceful case.
The derivation itself is gated and retried: the leader waits for the cluster’s partition repair to go quiet before scanning (bounded, so recovery still proceeds when the repair signal never settles), and a scan that fails transiently (for example on a member that is flapping while the cluster churns) is retried a bounded number of times with backoff before the rebalance is skipped and the loss reported loudly.
A crashed node that restarts at the same address (a container restart in place, the common Kubernetes case) is handled separately, because the cluster may never observe a NodeLeft for a fast restart: on startup, a node that finds registry records pointing at its own address with no corresponding local actor respawns the relocatable ones locally, exactly as crash relocation would have recreated them on a survivor. Singleton and non-relocatable records are removed instead: singletons are re-arbitrated by the leader on demand, and non-relocatable actors are lost with their incarnation by design.
Every relocation is announced by a RelocationStarted event on the event stream, listing the actor names and grain IDs in the relocation set; its BestEffort() accessor tells you whether the set comes from a graceful-shutdown snapshot (complete) or was reconstructed from the registry after a crash (possibly incomplete). See Relocation events.
Replication settings
Crash recovery is only as good as the registry’s replication. Registry records are partitioned by actor name, so the partitions a node owns hold a share of every node’s records; whatever is not replicated is lost with the node that owned it. The default configuration isreplicaCount=2 with writeQuorum=1 and readQuorum=1:
- Every registry partition has a backup on another node, so the loss of a single node is fully recoverable: the survivor’s backup copy is promoted before the recovery scan runs.
- The quorums stay at 1 so registry writes keep succeeding while a node is down. During the failure-detection window (the few seconds between a crash and the routing table dropping the dead member), writes to partitions where the dead node was primary or backup fail transiently; after the routing table updates, writes succeed against the reassigned owners.
- Quorum 1 does not weaken grain single activation: that is arbitrated by an atomic put-if-absent on the partition’s primary owner, not by read/write quorum overlap. Read repair is enabled, so a replica that missed a write is healed on the next read.
WithReplicaCount(3) to also tolerate two concurrent node losses, at the cost of one more synchronous write per registry update.
Cases that remain open at any replica count: losing all owners of a partition at once loses its records; a write acknowledged with a single copy (its backup replication failed and the key was never read again) is lost if its primary crashes; a full-cluster restart starts with an empty registry, which relocation does not cover regardless since no leader survives to rebalance.
Grain allocation
Grains are virtual actors, so they relocate lazily by default: when the hosting node departs, the runtime does not reactivate them up front. It only cleans the grain’s directory entry, and the grain re-activates on a surviving node the next time it is addressed (TellGrain/AskGrain). This avoids an OnActivate reactivation storm for grains that may never be called again. The cleanup work itself is distributed like any other relocation item (remainder to the leader, then chunks to peers), so it does not funnel through a single node.
Grains opted into eager relocation with WithGrainEagerRelocation are instead recreated up front on their target node, the same way actors are. Grains with WithGrainDisableRelocation are skipped entirely; they are lost with the node.
Configuration
Disable relocation for an actor
UseWithRelocationDisabled when spawning:
- Node-local state or resources (e.g. local files, device handles)
- Actors that cannot be safely recreated without external state
Disable relocation for a grain
Eager relocation for a grain
By default grains relocate lazily (reactivate on next use). Opt a grain into upfront reactivation withWithGrainEagerRelocation:
WithGrainEagerRelocation and WithGrainDisableRelocation are mutually exclusive; configuring both fails validation.Disable relocation system-wide
UseWithoutRelocation() when creating the actor system:
preShutdownskips building and persisting peer state- No actors or grains are relocated when nodes leave
- Useful for development, testing, or when you manage placement yourself
Child actors
Child actors are not relocatable by default. When a parent spawns a child viaSpawnChild, the child gets withRelocationDisabled() implicitly. Children are tied to their parent’s lifecycle; they are not independently relocated.
If a parent is relocated, its children are not relocated with it. They are recreated only as part of the parent’s PreStart (or equivalent) on the new node, if the parent explicitly spawns them again.
Relocatability requirements
For an actor to be relocated successfully:- Actor type must be registered (reflection) so the relocator can instantiate it.
- Dependencies must implement
Dependency(serializable). Pass viaWithDependencies(dep). - Supervisor, passivation, reentrancy, stashing, role: these are encoded in the actor’s serialized form and restored on the target node.
During relocation
- The actor may temporarily not exist: it is removed from the cluster map before being recreated on the target node.
- The actor’s logical identity (name, grain ID) is preserved; only the physical location (host:port) changes.
- Location transparency means you address by PID or grain ID; the framework routes to the new node once relocation completes.
Message handoff
Synchronous name-based sends automatically mask the brief handoff window. When you route a message to an actor whose host has just left the cluster,SendSync (and its ReceiveContext equivalent) detects that the target is being relocated and buffers the send by re-resolving and retrying with bounded backoff instead of failing immediately. Once the actor re-registers on a surviving node, the message is delivered there.
SendAsync is non-blocking by contract (it also backs rctx.SendAsync inside actor receive loops), so it never waits out a handoff. A target mid-relocation fails fast with ErrRelocationInProgress, a retryable signal, instead of being buffered or dialing the departed host.
Masking is bounded, not unbounded. Each node opens a short handoff window when it observes a departure; a
SendSync retries only within that window (never beyond its own timeout) and only while the target’s former host is still relocating. In steady state (no relocation in flight) sends resolve and deliver exactly once, adding no latency. If the window closes before the actor reappears, the send returns a retryable error:ErrActorNotFound: the actor could not be resolved on any surviving node.ErrRelocationInProgress: the target is still being relocated; retry shortly.
Check relocatability
Metrics
When OpenTelemetry metrics are enabled (WithMetrics), the leader records the outcome of each departed node’s relocation:
The duration, relocated, and failed instruments are tagged with
actor.system and relocation.node (the departed node’s address), and are only emitted on the node that performs the relocation (the leader). The buffered counter is tagged with actor.system and is emitted on any node that masks a send during a handoff (see Message handoff), so you can track how often callers hit the handoff window. When metrics are disabled every recording is a no-op.
See also
- Clustered Mode: Cluster setup and discovery
- Event Streams: Subscriber API and the full list of system events
- Singletons: Cluster singletons and placement
- Grains: Virtual actors and
WithGrainDisableRelocation - Extensions and Dependencies: Serializable dependencies for relocation
- Coordinated Shutdown: Shutdown sequence and
preShutdown